CamelCase
CamelCase — стиль написания составных слов, при котором части слова пишутся слитно, без разделителей, и каждая часть начинается с заглавной буквы и продолжается строчными.
Задание заключается в том, чтобы прочитать строку, заданную пользователем (возможно, с пробелами и другими символами), выбросить из нее все символы, не являющиеся буквами латинского алфавита, и объединить оставшиеся слова в одно составное слово, записанное в CamelCase.
Этот класс примеров демонстрирует чтение строк и дальнейшую с ними работу.
Тестовые примеры:
"Test Example One" -> "TestExampleOne"
" exampleTwo " -> "Exampletwo" (регистр исходных слов не имеет значения)
"!!! is_this_3RD EXAMPLE?.." -> "IsThisRdExample" (цифры и знаки препинания считаются разделителями)
Пример для версий Seed7 2012-01-01
В примере используется посимвольная обработка введенной строки.
$ include "seed7_05.s7i";
const proc: main is func
local
var string: text is "";
var string: camel_case is "";
var char: ch is ' ';
var boolean: was_space is TRUE;
begin
readln(text);
text := lower(text);
for ch range text do
if ch in {'a' .. 'z'} then
if was_space then
ch := upper(ch);
end if;
camel_case &:= ch;
was_space := FALSE;
else
was_space := TRUE;
end if;
end for;
writeln(camel_case);
end func;
Пример для версий Perl 5.12.1
В этом примере строка разбивается на части, разделенные небуквенными символами, затем к каждой части применяется функция ucfirst, переводящая ее в нужный регистр (команда map), и, наконец, все части конкатенируются командой join.
my $text = <STDIN>;
$text = join('', map(ucfirst, split(/[^a-z]+/, lc $text)));
print $text, "\n";
Пример для версий clisp 2.47, Corman Common Lisp 3.0, SBCL 1.0.1, SBCL 1.0.29
(defun camel-case (s)
(remove #\Space
(string-capitalize
(substitute #\Space nil s :key #'alpha-char-p))))
(princ (camel-case (read-line)))
Пример для версий Python 2.6.5
Используются функции стандартной библиотеки translate и title.
Для функции title все не-буквы считаются разделителями слов, так что нет необходимости предварительно заменять их пробелами.
non_letters = ''.join(c for c in map(chr, range(256)) if not c.isalpha())
def camel_case(s):
return s.title().translate(None, non_letters)
print camel_case(raw_input())
Пример для версий Groovy 1.7, Sun Java 6
В этом примере используются регулярные выражения Java. Регулярное выражение [a-zA-Z]+ описывает последовательность букв латинского алфавита в любом регистре, идущих подряд, окруженную другими символами или концами строки. Пара классов Pattern и Matcher позволяют создать это регулярное выражение и извлечь из строки все фрагменты, соответствующие ему. Для каждого такого фрагмента его первый символ переводится в верхний регистр, а последующие — в нижний, с использованием стандартных методов класса String. Наконец, результаты обработки фрагмента записываются в переменную типа StringBuffer, накапливающую результат.
import java.util.regex.*;
import java.io.*;
public class CamelCase {
public static void main(String[] args) {
try {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Pattern p = Pattern.compile("[a-zA-Z]+");
Matcher m = p.matcher(br.readLine());
StringBuffer result = new StringBuffer();
String word;
while (m.find()) {
word = m.group();
result.append(word.substring(0, 1).toUpperCase() + word.substring(1).toLowerCase());
}
System.out.println(result.toString());
} catch (Exception e) {
System.err.println("An error occured while reading input string.");
}
}
}
Пример для версий vbnc 2.4.2
В этом примере каждый символ строки проверяется на принадлежность к латинскому алфавиту и в случае отрицательного результата заменяется на пробел. После этого строка переводится в Proper Case (все слова пишутся прописными буквами и начинаются с заглавной), и наконец, все пробелы убираются из строки.
Module Module1
Sub Main()
Dim Text As String
Dim i As Long
Try
Text = LCase(Console.ReadLine())
Catch ex As Exception
Console.WriteLine("Invalid input.")
Return
End Try
For i = 1 To Len(Text) Step 1
If InStr("abcdefghijklmnopqrstuvwxyz", GetChar(Text, i)) = 0 Then
Text = Replace(Text, GetChar(Text, i), " ")
End If
Next
Console.WriteLine(Replace(StrConv(Text, vbProperCase), " ", ""))
End Sub
End Module
Пример для версий SpiderMonkey (Firefox 3.5)
Пример выполняется в веб-браузере, точно так же, как квадратное уравнение. Форма ввода должна выглядеть следующим образом:
<form name="CamelCase">
<input type="text" required="required" name="txt">
<input type="button" value="Convert to CamelCase" onClick="convert()">
</form>
Сам код можно было бы записать в одну строчку, но он разбит на несколько частей для улучшения читабельности. Первая строка получает строку для обработки; вторая переводит ее в нижний регистр и заменяет все не-буквы пробелами. Третья строка переводит в верхний регистр первый символ каждого слова; наконец, четвертая строка убирает все пробелы. В JavaScript активно используются регулярные выражения, поэтому все действия производятся с их помощью.
function convert() {
txt = document.CamelCase.txt.value;
txt = txt.toLowerCase().replace(/[^a-z ]+/g, ' ');
txt = txt.replace(/^(.)|\s(.)/g, function($1) { return $1.toUpperCase(); });
txt = txt.replace(/[^a-zA-Z]+/g, '');
document.getElementById('output').innerHTML = txt;
}
Пример для версий Borland C++ Builder 6, g++ 4.x, Microsoft Visual C++ 9 (2008)
Эта программа обрабатывает введенную строку посимвольно. Функция getline считывает из потока ввода, заданного первым аргументом, строку (не до пробела, а до конца строки) и записывает ее во второй аргумент. Стандартная функция tolower работает только с одиночными символами, поэтому для преобразования в нижний регистр строки целиком используется функция transform, которая применяет заданную функцию ко всем элементам вектора (а в STL строка — это вектор символов). Затем для каждого символа строки проверяется, является ли он символом алфавита (функция isalpha), и в зависимости от результата он либо дописывается в конец результирующей строки (в верхнем регистре, если перед ним был не-алфавитный символ), либо устанавливает признак “последний символ был пробелом”. Функция isalpha работает с символами любого регистра, поэтому перевод в нижний регистр можно было делать не отдельным действием над всей строкой, а при присоединении каждого отдельного символа.
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
string text, cc="";
bool lastSpace = true;
getline(cin, text);
transform(text.begin(), text.end(), text.begin(), (int (*)(int))tolower);
for (int i=0; i<text.size(); i++)
if (isalpha(text[i])) {
if (lastSpace)
cc += toupper(text[i]);
else
cc += text[i];
lastSpace = false;
}
else {
lastSpace = true;
}
cout << cc << endl;
return 0;
}
Пример для версий gcc 3.4.5, gcc 3.4.5 (Objective-C), TCC 0.9.25
Пример основан на посимвольной обработке строки. Функция gets читает строку до конца строки. Следует отметить, что эта функция считается “опасной” из-за отсутствия контроля того, сколько символов введено, и возможных ошибках доступа к памяти. В C нет логического типа данных, поэтому его приходится симулировать целой переменной.
#include <stdio.h>
void main() {
char text[100],cc[100];
gets(text);
int i,j=0,lastSpace=1;
for (i=0; text[i]!='\0'; i++)
if (text[i]>='A' && text[i]<='Z' || text[i]>='a' && text[i]<='z')
{ if (lastSpace>0)
cc[j] = toupper(text[i]);
else
cc[j] = tolower(text[i]);
j++;
lastSpace = 0;
}
else
lastSpace = 1;
cc[j]='\0';
printf("%s\n",cc);
}
Пример для версий Oracle 10g SQL, Oracle 11g SQL
В этом примере используются регулярные выражения Oracle SQL. Первым действием функция regexp_replace заменяет все цифры на пробелы — это необходимо для initcap, которая считает цифры частью слов и не переводит буквы, следующие за цифрами, в верхний регистр. Затем применяется initcap, которая переводит все слова в нижний регистр, а их первые буквы — в верхний. Наконец, второе использование regexp_replace удаляет из строки все знаки пунктуации и пробелы.
select regexp_replace(initcap(regexp_replace('&TEXT', '[[:digit:]]', ' ')), '([[:punct:] | [:blank:]])', '')
from dual
Пример для версий Free Pascal 2.2.0, Free Pascal 2.2.4, gpc 20070904, Turbo Pascal 4.0, Turbo Pascal 5.0, Turbo Pascal 5.5, Turbo Pascal 6.0
Программа обрабатывает строку посимвольно. Для определения того, является ли символ буквой, и если является, то в каком он регистре, используются ASCII-коды символов. Функция ord возвращает ASCII-код данного символа, а chr — символ по его коду. Размерность строк не задана и по умолчанию принимается равной 255.
Отметим, что в Turbo Pascal программа работает только начиная с версии 4.0; в более ранних версиях не было типа данных char.
program Camelcase;
var
text, cc: string;
c: char;
i: integer;
lastSpace: boolean;
begin
readln(text);
lastSpace := true;
cc := '';
for i := 1 to Length(text) do
begin
c := text[i];
if ((c >= #65) and (c <= #90)) or ((c >= #97) and (c <= #122)) then
begin
if (lastSpace) then
begin
if ((c >= #97) and (c <= #122)) then
c := chr(ord(c) - 32);
end
else
if ((c >= #65) and (c <= #90)) then
c := chr(ord(c) + 32);
cc := cc + c;
lastSpace := false;
end
else
lastSpace := true;
end;
writeln(cc);
end.
Пример для версий Free Pascal 2.2.0, Free Pascal 2.2.4, gpc 20070904, Turbo Pascal 4.0, Turbo Pascal 5.0, Turbo Pascal 5.5, Turbo Pascal 6.0
Пример использует такую же логику, как и предыдущий, но для проверки того, является ли символ буквой, используются множества символов lower и upper. Это делает код более читабельным.
Отметим, что в Turbo Pascal программа работает, начиная с версии Turbo Pascal 4.0, в которой впервые появляется тип данных char.
program Camelcase;
var
text, cc: string[100];
c: char;
i: integer;
lastSpace: boolean;
upper, lower: set of char;
begin
upper := ['A'..'Z'];
lower := ['a'..'z'];
readln(text);
lastSpace := true;
cc := '';
for i := 1 to Length(text) do
begin
c := text[i];
if (c in lower) or (c in upper) then
begin
if (lastSpace) then { convert to uppercase }
begin
if (c in lower) then
c := chr(ord(c) - 32);
end
else { convert to lowercase }
if (c in upper) then
c := chr(ord(c) + 32);
cc := cc + c;
lastSpace := false;
end
else
lastSpace := true;
end;
writeln(cc);
end.
Пример для версий gmcs 2.0.1
Первая строка метода Main читает из консоли строку и переводит ее в нижний регистр. Вторая строка заменяет все последовательности из 1 и более не-буквы пробелами. Третья и четвертая строки получают объект класса TextInfo и используют его для того, чтобы перевести строку в Title Case (каждое слово начинается с большой буквы). Наконец, из полученной строки удаляются все пробелы (методом замены строки из одного пробела на пустую строку), и результат выводится на печать.
using System;
using System.Globalization;
using System.Text.RegularExpressions;
public class Program
{ public static void Main(string[] args)
{ string text = Console.ReadLine().ToLower();
text = Regex.Replace(text,"([^a-z]+)"," ");
TextInfo ti = new CultureInfo("en-US",false).TextInfo;
text = ti.ToTitleCase(text);
text = text.Replace(" ","");
Console.WriteLine(text);
}
}
Пример для версий gmcs 2.0.1
Этот пример использует только регулярные выражения. Первое обращение к ним заменяет все максимальные последовательности букв в строке на результат применения к ним функции CapitalizePart, то есть переводит первый символ в верхний регистр. Второе — заменяет все не-буквы на пустые строки.
using System;
using System.Text.RegularExpressions;
class Program
{ static string CapitalizePart(Match m)
{ string x = m.ToString();
return char.ToUpper(x[0]) + x.Substring(1, x.Length-1);
}
static void Main()
{ string text = Console.ReadLine().ToLower();
string cc = Regex.Replace(text, "([a-z]+)", new MatchEvaluator(Program.CapitalizePart));
cc = Regex.Replace(cc, "[^a-zA-Z]+", string.Empty);
Console.WriteLine(cc);
}
}
Пример для версий Ruby 1.9.2
Функция gets.chomp читает строку из стандартного потока ввода. Функция split с аргументом-регулярным выражением разбивает строку на части, разделенные подстроками, которые соответствуют этому выражению. Затем к каждой части применяется функция capitalize, которая переводит всю строку в нижний регистр, а первый символ — в верхний. Наконец, части строки объединяются в одну строку.
puts gets.chomp.split( /[^a-zA-Z]+/ ).map {|w| w.capitalize}.join
Пример для версий Ruby 1.9.2
Пример работает точно так же, как этот пример, но функция scan извлекает из строки части, которые соответствуют регулярному выражению, а не отбрасывает их, как это делает split.
puts gets.chomp.scan( /[a-zA-Z]+/ ).map {|w| w.capitalize}.join
Пример для версий Scala 2.8.0-final
Этот пример использует два разных регулярных выражения. Первое, words, описывает слова текста; все подстроки, подходящие под это выражение, переводятся в нижний регистр с первой буквой верхнего регистра. Второе, separators, описывает промежутки между словами, которые просто удаляются из строки.
import java.io.{BufferedReader, InputStreamReader}
import scala.util.matching.Regex
object Main {
def main(args: Array[String]) {
var stdin = new BufferedReader(new InputStreamReader(System.in));
var text = stdin.readLine();
val words = """([a-zA-Z]+)""".r
text = words.replaceAllIn(text, m => m.matched.toLowerCase.capitalize)
val separators = """([^a-zA-Z]+)""".r
text = separators.replaceAllIn(text, "");
println(text);
}
}
Пример для версий Scratch 1.4
Эту задачу нельзя решить с использованием только стандартных блоков Scratch; придется воспользоваться скрытыми возможностями среды разработки. В этом руководстве детально описано, как добавить к стандартным блокам еще два, которые будут преобразовывать символ в его ASCII-код (блок “ascii code of _”) и наоборот (“ascii _ as letter”). После добавления этих блоков остаток программы вполне тривиален.
Отметим, что индекс массива начинается с 1, а в условиях циклов и условных переходов логические значения приходится сравнивать с true и false в явном виде.
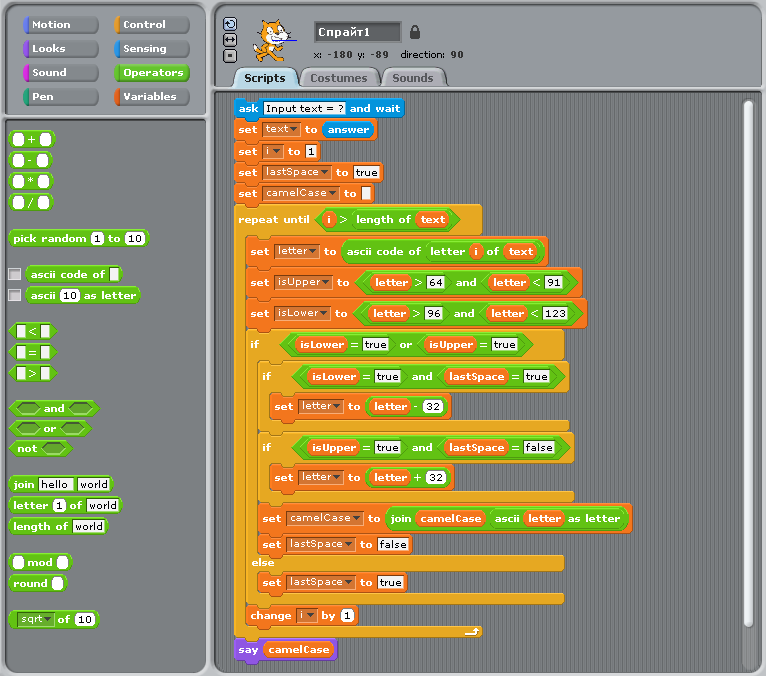
CamelCase на Scratch
Пример для версий Sanscript 2.2
На первой диаграмме текст, введенный пользователем, переводится в нижний регистр и передается в цикл посимвольной обработки. На второй — блок Split Text используется для выделения очередного символа строки, который затем сравнивается со строками-ограничителями (ASCII-коды которых равны a-1 и z+1), и результат сравнения передается в блок выбора действия. На третьей — если символ является буквой, то в зависимости от значения lastSpace к результату добавляется либо сам символ, либо он же, переведенный в верхний регистр; кроме того, значение lastSpace устанавливается в FALSE. На четвертой — если символ не является буквой, то только изменяется значение lastSpace.
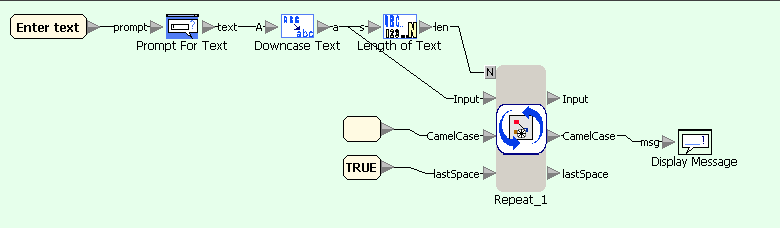
CamelCase - главная диаграмма потоков
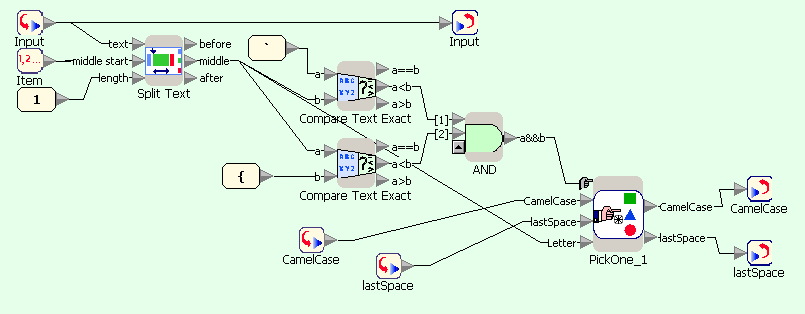
CamelCase - блок Repeat
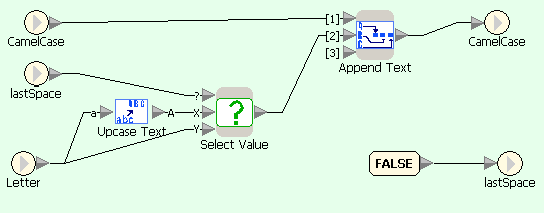
CamelCase - обработка символа-буквы
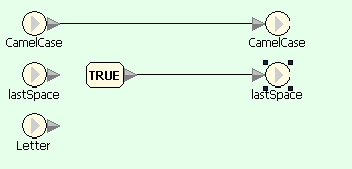
CamelCase - обработка символа-разделителя
Пример для версий PHP 5.3.2
Используются строковые функции и регулярные выражения. Функция ucwords переводит первую букву каждого слова в верхний регистр.
<?
$text = fgets(STDIN);
$text = str_replace(' ', '', ucwords(preg_replace('/[^a-z]/', ' ', strtolower($text))));
echo $text;
?>
Пример для версий Baltie 3
В примере показана стандартная посимвольная обработка строки. Отметим, что язык не поддерживает переменные логического типа, поэтому признак “последний символ был разделителем” приходится хранить в переменной целочисленного типа. Baltie 3 — язык со строгой типизацией, поэтому преобразование символа в ASCII-код приходится выполнять в явном виде.
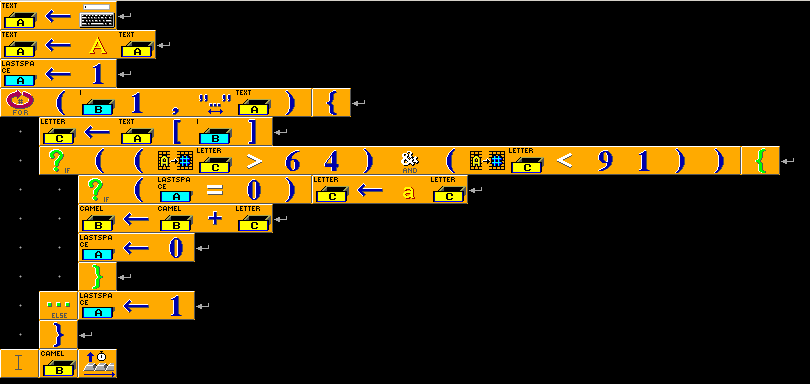
CamelCase на Baltie 3
Пример для версий Io-2008-01-07
В примере показана стандартная посимвольная обработка строки. Отметим, что метод at(i) возвращает ASCII-код i-ого символа строки, а slice(i,i+1) — символ как строку длины 1. Для определения, является ли символ буквой, использован его ASCII-код, а для перевода в верхний регистр и вывода на печать — сам символ.
S := File standardInput readLine asLowercase;
lastSpace := 1;
for(i,0,(S size)-1,
ascii := S at(i);
letter := S slice(i,i+1);
if(ascii>=97 and ascii<=122,
if(lastSpace==1, letter := letter asUppercase);
letter print;
lastSpace := 0,
lastSpace := 1;
);
);
Пример для версий ActiveTcl 8.5, JTcl 2.1.0, Tcl 8.4, Tcl 8.5.7
Строка обрабатывается посимвольно. Для проверки того, что символ является буквой, используется регулярное выражение.
set S [gets stdin]
set S [string tolower $S]
set L [string length $S]
set lastSpace 1
set cc ""
for {set i 0} {$i < $L} {incr i} {
set letter [string index $S $i]
if { [string match {[a-z]} $letter] } {
if { $lastSpace == 1 } { set letter [string toupper $letter] }
append cc $letter
set lastSpace 0
} else {
set lastSpace 1
}
}
puts $cc
Пример для версий D 2.009
Первая строка читает строку из стандартного потока ввода и переводит ее в нижний регистр. Вторая — заменяет все символы, не являющиеся буквами латинского алфавита, на пробелы (последний параметр — атрибуты замены, “g” означает, что замена выполняется во всей строке, а не только в первом подходящем месте). Третья — использует стандартную функцию capwords для того, чтобы убрать пробелы из начала и конца строки, заменить последовательности нескольких пробелов на один пробел и перевести первую букву каждого слова в верхний регистр. Наконец, все оставшиеся пробелы удаляются из строки, и результат выводится на печать.
import std.stdio;
import std.string;
import std.regexp;
void main() {
string text = tolower(readln());
text = sub(text,"[^a-z]"," ","g");
text = capwords(text);
text = sub(text," ","","g");
writeln(text);
}
Пример для версий Perl 5.12.1
Первая строка читает строку для обработки. Вторая — заменяет все не-буквы на пробелы; для этого используется операция замены регулярных выражений c опцией g, которая ищет все соответствия паттерну в строке. Третья строка переводит в верхний регистр первую букву каждого слова и в нижний — следующие буквы. Паттерн \b(\w+)\b соответствует максимальному одиночному слову (окруженному со всех сторон пробелами). Переменная $1 в выражении замены содержит слово, соответствующее паттерну. Выражение замены ucfirst($1) в сочетании с опцией /e заменяет слово на результат вычисления этой функции от него (/e активирует интерполяцию переменных в строке). Наконец, четвертая строка удаляет все пробелы из строки.
Во всех действиях с регулярными выражениями используется оператор привязки =~, который позволяет применять их к произвольной переменной, а не к переменной по умолчанию $_.
$A = <>;
$A =~ s/[^a-zA-Z]+/ /g;
$A =~ s/\b(\w+)\b/ucfirst($1)/ge;
$A =~ s/[ ]+//g;
print $A;
Пример для версий rakudo-2010.08
Первая строка читает строку для обработки. Вторая — объявляет строковую переменную, в которой будет формироваться результат.
В третьей строке происходит самое интересное: регулярное выражение <[a..zA..Z]>+ ищет в строке все “слова” — максимальные последовательности букв. Для каждого найденного слова выполняется встроенный в регулярное выражение код { $cc ~= $0.capitalize; }, который переводит его в нужный регистр и дописывает в результат. Наконец, результат $cc выводится на печать.
my $A = $*IN.get;
my $cc = "";
$A ~~ s:g /(<[a..zA..Z]>+) { $cc ~= $0.capitalize; } //;
print $cc;
Пример для версий gawk 3.1.6
В переменной $0 хранится вся прочитанная запись-строка (в отличие от переменных $1, $2, …, в которых хранятся поля этой записи). Функция split разбивает строку text на фрагменты, разделенные строками, каждая из которых соответствует регулярному выражению, и записывает их в массив words. После этого каждый элемент words переводится в правильный регистр по частям функциями substr, toupper и tolower.
{ text = $0;
split(text, words, /[^a-zA-Z]+/);
for (i=1; i<=length(words); i++) {
res = res toupper(substr(words[i],1,1)) tolower(substr(words[i],2));
}
print res
}
Пример для версий gawk 3.1.6, Jawk 1.02, mawk 1.3.3
В реализации mawk нет функции length для определения количества элементов массива. В реализации Jawk ее также нельзя использовать — возникает ошибка “Cannot evaluate an unindexed array.”.
Вместо этого во всех реализациях можно использовать то, что функция split возвращает количество полученных ею фрагментов. В остальном этот пример аналогичен примеру для gawk.
{ text = $0;
N = split(text, words, /[^a-zA-Z]+/);
for (i=1; i<=N; i++) {
res = res toupper(substr(words[i],1,1)) tolower(substr(words[i],2));
}
print res
}
Пример для версий Lua 5.1
Создатели Lua ставили себе за цель создание максимально легкого языка, поэтому вместо полноценных регулярных выражений язык поддерживает pattern matching. Впрочем, это позволяет реализовать большинство функций регулярных выражений без лишних трудозатрат.
В данном примере первая строка читает строку для преобразования; функция io.read() без аргумента читает строчный тип. Вторая строка изменяет регистр каждой последовательности букв к нужному; паттерн %a соответствует букве в любом регистре, и для каждого соответствия паттерну вызывается анонимная функция, выполняющая преобразование. Третья строка убирает все последовательности не-букв, и, наконец, четвертая выводит результат на печать.
text = io.read()
text = text.gsub(text, '[%a]+', function(s)
return string.upper(string.sub(s,1,1)) .. string.lower(string.sub(s,2))
end)
text = text.gsub(text, '[%A]+', '')
io.write(text)
Пример для версий iconc 9.4
Прежде всего программа читает строку для обработки в переменную text и добавляет в конец пробел (|| — оператор конкатенации). Затем переменная text сканируется (? — оператор сканирования, позволяющий привязать все операции поиска в строке к определенной переменной) следующим образом.
Команды ReFind и ReMatch из библиотеки регулярных выражений regexp находят все последовательности символов, соответствующие регулярному выражению, но ReFind возвращает индекс начала последовательности, а ReMatch — первого символа после последовательности. За одну итерацию цикла ReFind находит начало следующей последовательности не-букв. Команда tab перемещает указатель на текущую позицию в сканируемой строке на это начало и возвращает подстроку от предыдущей позиции до новой — слово. Затем слово преобразуется к нужному формату и добавляется к результату. *word — функция, возвращающая длину строки word. map заменяет символы первого аргумента, которые есть во втором, на их соответствия из третьего (в данном случае — заменяет друг на друга символы из &lcase и &ucase, встроенных переменных, содержащих алфавит в нижнем и верхнем регистре, соответственно). Наконец, еще одно обращение к tab перемещает указатель на начало следующего слова (конец последовательности не-букв).
link regexp
procedure main ()
text := read() || " ";
cc := "";
text ? {
while j := ReFind("[^a-zA-Z]+") do {
word := tab(j);
cc ||:= map(word[1],&lcase,&ucase) || map(word[2:*word+1],&ucase,&lcase);
tab(ReMatch("[^a-zA-Z]+"));
}
}
write (cc);
end
Пример для версий gst 3.1
text := stdin nextLine asLowercase.
text := text replacingAllRegex: '([^a-zA-Z]+)' with: ' '.
cc := ''.
text onOccurrencesOfRegex: '\b(\w+)\b' do: [ :each |
word := each match.
cc := cc,((word copyFrom: 1 to: 1) asUppercase),(word copyFrom: 2 to: (word size)).
].
cc displayNl.
Пример для версий Bash 4.0.35, Bash 4.1.5
Используются регулярные выражения. Первая строка читает с консоли строку для обработки $text. Вторая — переводит ее в нижний регистр. Затем в полученной строке ищутся последовательности букв — слова — по одному за раз. Каждое слово выделяется (переменная BASH_REMATCH содержит информацию о последовательности символов, которая соответствует регулярному выражению, которое в последний раз искали в строке), заменяется на пробел в исходной строке (во избежание повторного нахождения) и добавляется к результату $cc в нужном регистре (функция ${word^} переводит первый символ аргумента в верхний регистр). Наконец, результат выводится на печать.
read text
text=${text,,}
cc=""
regex='([a-z]+)'
while [[ $text =~ $regex ]]
do
word=${BASH_REMATCH[1]}
text=${text/$word/ }
cc=$cc${word^}
done
echo $cc
Пример для версий Roco 20071014
Пример подробно прокомментирован. Сопрограмма char считывает символы в цикле и определяет, являются ли они буквами. Для обработки символов, окозавшихся буквами, вызывается другая сопрограмма, letter, которая переводит их в нужный регистр и выводит. Отметим, что команда not инвертирует все биты числа, поэтому ее нельзя использовать для инверсии логического значения (0 или 1) — для этого приходится вычитать исходное значение из единицы.
/* [0] - current character
[1] - last character was space?
rest are temporary variables (used within one iteration only)
*/
co letter{
/* coroutine to process the case of a known letter */
/* if it is uppercase, and last one was letter, change to lowercase */
sub [4] 1 [1]
and [5] [2] [4]
if [5]
add [0] [0] 32
/* if it is lowercase, and last one was space, change to uppercase */
and [5] [3] [1]
if [5]
sub [0] [0] 32
/* print the character */
cout [0]
set [1] 0
ac
}
co char{
/* read next character to [0] */
cin [0]
/* break the loop when the next character is end-of-line (ASCII 10) */
eq [2] [0] 10
if [2] ac
/* check whether this character is a letter at all [2] - uppercase, [3] - lowercase, [4] - at all, [5]-[6] - temporary */
/* uppercase */
gt [5] [0] 64
lt [6] [0] 91
and [2] [5] [6]
/* lowercase */
gt [5] [0] 96
lt [6] [0] 123
and [3] [5] [6]
/* at all */
or [4] [2] [3]
sub [5] 1 [4]
/* if this is not a letter, ONLY change [1] */
if [5]
set [1] 1
/* otherwise, call the coroutine to handle this */
if [4]
ca letter
}
/* at the start mark that last character was space */
set [1] 1
ca char
ac
Пример для версий Pike 7.6, Pike 7.8
Эта программа обрабатывает введенную строку посимвольно. Единственный нюанс — в системе типов Pike отсутствует тип “символ”, поэтому text[i] — не строка, а число — ASCII-код символа. Чтобы получить строку, нужно использовать text[i..i] — операцию извлечения подстроки.
int main() {
string text = lower_case(Stdio.stdin->gets()), cc = "";
int i, lastSpace = 1;
for (i=0; i<strlen(text); i++) {
if (text[i] >= 'a' && text[i] <= 'z') {
if (lastSpace == 1)
cc += upper_case(text[i..i]);
else
cc += text[i..i];
lastSpace = 0;
}
else
lastSpace = 1;
}
write(cc+"\n");
return 0;
}
Пример для версий befungee 0.2.0
Программа реализует посимвольную обработку введенной строки. Код снаружи цикла 152p записывает в ячейку программы (5,2) значение 1, соответствующее логическому true — начало строки считается пробелом.
Основная часть программы — цикл. В одной итерации цикла считывается (~) и обрабатывается один символ. Выход из цикла осуществляется, если ASCII-код введенного символа равен 10 (: 25*- #v_ @), в противном случае указатель инструкций отправляется во вторую строку (команда v). Если символ — буква нижнего регистра, он переводится в верхний — для единообразия последующей обработки (часть программы до первого квадратного блока и сам блок). Затем аналогичным способом проверяется, является ли символ буквой верхнего регистра. Если нет (переход в первую строку), в ячейку (5,2) снова записывается 1, символ удаляется из стека, и цикл заканчивается. Если да (переход в третью строку), выполняется еще одна проверка — на значение ячейки (5,2), в зависимости от которого символ остается собой или переводится в нижний регистр. Наконец, символ выводится, и цикл заканчивается.
152p > ~ : 25*- #v_ @ >48*-v >152p $ v
> :: "`"` \"{"\` * | > :: "@"` \"["\` * ! | > v
> ^ >52g | >052p,v
>48*+^
^ <
( )
|
was last character a space? (5,2)
Пример для версий Whitespacers (Ruby)
push-1 { }
push-1 { }
save LOOP-START.label-0
{ }
push-2 { }
readchar
push-2 { }
load CHECK-WHETHER-IS-EOL.duplicate
push-10 { }
subtract if-0-goto-1
{ }
CONVERT-TO-LOWERCASE.duplicate
push-A { }
subtract if-neg-goto-2
{ }
duplicate
push-Z { }
swap
subtract if-neg-goto-2
{ }
push-32 { }
add label-2
{ }
CHECK-WHETHER-IS-LETTER.duplicate
push-a { }
subtract if-neg-goto-3
{ }
duplicate
push-z { }
swap
subtract if-neg-goto-3
{ }
ACTION-IF-LETTER.CHECK-WHETHER-LAST-WAS-SPACE.push-1 { }
load if-0-goto-4
{ }
push-32 { }
subtract label-4
{ }
print
push-1 { }
push-0 { }
save goto-0
{ }
label-3
{ }
ACTION-IF-NOT-LETTER.push-1 { }
push-1 { }
save goto-0
{ }
label-1
{ }
push-10 { }
print
end.memory:1-was-last-space,2-currentchar
Пример для версий Morphett's FALSE
Введенная строка обрабатывается посимвольно. В Morphett’s FALSE строки вводятся во всплывающем окне, и признаком конца ввода является пустая строка, которая преобразуется в значение -1; поэтому в качестве признака конца цикла используется -1. Условное выполнение команд ? позволяет только выполнить команду, если условие истинно; для реализации ветви else приходится дублировать условие (переменная l), инвертировать его и использовать еще один оператор ?.
1_s: ^
[$1_=~]
[ $$ 96> \123\> & [32-]?
$$ 64> \91\> & $l: [s;~[32+]? , 0s:]? l;~[1_s: %]?
^]
#
Пример для версий Perl 5.12.1
Этот пример работает так же, как этот, но для разбития строки на слова используется регулярное выражение, выделяющее максимальные последовательности букв
my $text = <STDIN>;
$text = join('', map(ucfirst, lc($text) =~ /[a-z]+/g));
print "$text\n";
Пример для версий gcc 3.4.5 (Objective-C)
#import <Foundation/Foundation.h>
#define LETTERS @"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
NSString *camelCase(NSString *s) {
return [[[s capitalizedString] componentsSeparatedByCharactersInSet:[[NSCharacterSet characterSetWithCharactersInString:LETTERS] invertedSet]] componentsJoinedByString:@""];
}
int main (int argc, const char * argv[]) {
NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init];
NSLog(@"%@", camelCase(@"Test Example One"));
NSLog(@"%@", camelCase(@"exampleTwo "));
NSLog(@"%@", camelCase(@"!!! is_this_3RD EXAMPLE?.."));
[pool drain];
return 0;
}
Пример для версий SML/NJ 110.69
val text = valOf (TextIO.inputLine TextIO.stdIn);
fun capitalize s = let
val (x::xs) = explode s
in
implode (Char.toUpper x :: map Char.toLower xs)
end;
val result = concat (map capitalize (String.tokens (not o Char.isAlpha) text));
print (result ^ "\n");
Пример для версий Falcon 0.9.6.6
В этом примере показана посимвольная обработка введенной строки.
text = input().lower()
cc = ""
was_space = true
for i in [ 0 : text.len() ]
if text[i] >= 'a' and text[i] <= 'z'
if was_space
cc += text[i].upper()
else
cc += text[i]
end
was_space = false
else
was_space = true
end
end
printl(cc)
Пример для версий Factor 0.94
В этом примере используются регулярные выражения. Слово re-split (словарь regexp) разбивает строку на массив подстрок, разделенных заданным регулярным выражением. Затем комбинатор map применяет к каждому элементу массива слово >title (unicode.case), которое переводит первый символ строки в верхний регистр, а остальные — в нижний. Наконец, join (sequences) конкатенирует строки массива в одну с разделителем “”.
USING: kernel io regexp sequences unicode.case ;
readln R/ [^a-zA-Z]+/ re-split
[ >title ] map
"" join print
Пример для версий Oracle 11g SQL
В этом примере используются регулярные выражения Oracle SQL в сочетании с PL/SQL. Функция regexp_substr возвращает подстроку text, являющуюся соответствием заданному регулярному выражению номер occurrence.
declare
text varchar2(100) := '&user_input';
word varchar2(100);
camelcase varchar2(100);
occurrence number := 1;
begin
loop
word := regexp_substr(text, '[[:alpha:]]+', 1, occurrence);
exit when word is null;
camelcase := camelcase || initcap(word);
occurrence := occurrence + 1;
end loop;
dbms_output.put_line(camelcase);
end;
Пример для версий loljs 1.1
Отметим, что в LOLCODE нет функций работы со строками и символами, кроме конкатенации — например, символы нельзя сравнивать BIGGR OF или SMALLR OF или получить их ASCII-коды. Поэтому для определения того, является ли символ буквой, и перевода его в другой регистр приходится создавать “словари” букв и искать в них нужную перебором.
HAI
I HAS A UPP ITZ "QWERTYUIOPASDFGHJKLZXCVBNM"
I HAS A LOW ITZ "qwertyuiopasdfghjklzxcvbnm"
HOW DUZ I LOWER CHAR
I HAS A I ITZ 0
IM IN YR LOOP UPPIN YR I TIL BOTH SAEM I AN LEN OF UPP
BOTH SAEM UPP!I AN CHAR, O RLY?
YA RLY
FOUND YR LOW!I
OIC
IM OUTTA YR LOOP
FOUND YR CHAR
IF U SAY SO
HOW DUZ I UPPER CHAR
I HAS A I ITZ 0
IM IN YR LOOP UPPIN YR I TIL BOTH SAEM I AN LEN OF UPP
BOTH SAEM LOW!I AN CHAR, O RLY?
YA RLY
FOUND YR UPP!I
OIC
IM OUTTA YR LOOP
FOUND YR CHAR
IF U SAY SO
HOW DUZ I ISLOWER CHAR
I HAS A I ITZ 0
IM IN YR LOOP UPPIN YR I TIL BOTH SAEM I AN LEN OF UPP
BOTH SAEM LOW!I AN CHAR, O RLY?
YA RLY
FOUND YR WIN
OIC
IM OUTTA YR LOOP
FOUND YR FAIL
IF U SAY SO
I HAS A TEXT
GIMMEH TEXT
I HAS A CAMELCASE ITZ ""
I HAS A I ITZ 0
I HAS A SPACE ITZ WIN
IM IN YR LOOP UPPIN YR I TIL BOTH SAEM I AN LEN OF TEXT
I HAS A CHAR ITZ LOWER TEXT!I
ISLOWER CHAR, O RLY?
YA RLY
BTW this is a letter (already lowercase), modify depending on SPACE
SPACE, O RLY?
YA RLY
CHAR R UPPER CHAR
OIC
CAMELCASE R SMOOSH CAMELCASE CHAR
SPACE R FAIL
NO WAI
BTW this is space - mark it
SPACE R WIN
OIC
IM OUTTA YR LOOP
VISIBLE CAMELCASE
KTHXBYE
Пример для версий Nimrod 0.8.8
Эта программа использует регулярные выражения. В Nimrod они реализованы при помощи библиотеки PRCE (Perl-Compatible Regular Expressions), написанной на C.
from strutils import toLower, capitalize, join
import re
var text = toLower(readLine(stdin))
var words = split(text, re"[^a-z]+")
echo join(words.each(capitalize))
Пример для версий VBA 6.3, VBA 6.5
Sub CamelCase()
Dim Text As String
Text = LCase(Application.InputBox("Enter Text"))
For i = 1 To Len(Text) Step 1
If InStr("abcdefghijklmnopqrstuvwxyz", Mid(Text, i, 1)) = 0 Then
Text = Replace(Text, Mid(Text, i, 1), " ")
End If
Next i
MsgBox (Replace(StrConv(Text, vbProperCase), " ", ""))
End Sub
Пример для версий VBScript 5.7, VBScript 5.8
В отличие от многих других реализаций Visual Basic, в VBScript нет функции StrConv. Поэтому проще всего выполнить нужное преобразование строки посимвольно.
Text = LCase(WScript.StdIn.ReadLine)
CamelCase = ""
WasSpace = True
For i = 1 To Len(Text)
Ch = Mid(Text, i, 1)
If InStr("abcdefghijklmnopqrstuvwxyz", Ch) = 0 Then
WasSpace = True
Else
If WasSpace Then
CamelCase = CamelCase & UCase(Ch)
Else
CamelCase = CamelCase & Ch
End If
WasSpace = False
End If
Next
WScript.Echo CamelCase
Пример для версий gnat 3.4.5
with Ada.Text_IO,
Ada.Characters.Handling;
use Ada.Text_IO,
Ada.Characters.Handling;
procedure CamelCase is
Text: String(1..100);
Length: Natural;
Was_Space: Boolean := True;
I: Integer := 1;
begin
Get_Line(Text, Length);
Text := To_Lower(Text);
loop
if Character'Pos(Text(I)) > 96 and Character'Pos(Text(I)) < 123 then
if Was_Space then
Put(To_Upper(Text(I)));
else
Put(Text(I));
end if;
Was_Space := False;
else
Was_Space := True;
end if;
I := I + 1;
exit when I > Length;
end loop;
end;
Пример для версий guile 1.8.5
В этом примере показана работа с регулярными выражениями из модуля regex. Первые две строки подключают нужные модули. Третья — читает строку из входных данных командой read-line (модуль rdelim) — в отличие от read, она читает все символы до конца строки, а не до первого пробела — и переводит ее в нижний регистр.
Четвертая команда находит все последовательности букв нижнего регистра в строке. Для каждой такой последовательности она заменяет ее на результат применения к ней некоторой функции (привязанной с помощью lambda). В данном случае это функция string-titlecase, переводящая первый символ строки в верхний регистр.
Наконец, пятая команда удаляет из строки все символы, не являющиеся буквами.
(use-modules (ice-9 regex))
(use-modules (ice-9 rdelim))
(define text (string-downcase (read-line)))
(define text (regexp-substitute/global #f "[a-z]+" text 'pre (lambda (m) (string-titlecase (match:substring m))) 'post))
(define text (regexp-substitute/global #f "[^a-zA-Z]+" text 'pre 'post))
(display text)
Пример для версий f2c 20090411, g95 0.93, gfortran 4.5.0
Строки в Fortran имеют фиксированную длину, задаваемую при объявлении строки. Если длина фактического содержимого строки меньше, чем размер строки, ее остаток дополняется пробелами или “мусорными” символами. Кроме того, в Fortran нет символа “конца строки”, как в C. Из-за этого после посимвольного заполнения строки CC, содержащей результат, остаток строки приходится заполнять пробелами вручную.
Проверка того, что очередной символ исходной строки является буквой, слишком длинна, чтобы поместиться в одну строку (все символы строки программы, начиная с 73-ей позиции, игнорируются), поэтому ее приходится разбивать на две строки и отмечать вторую как продолжение первой (любым символом в 6 позиции).
Операторы сравнения в FORTRAN 77 записываются как .LE., .GE. и т.д. из-за того, что символы > и < не входят в набор символов языка; они были добавлены только в Fortran 90.
PROGRAM CAMELC
CHARACTER TEXT*30, CC*30
LOGICAL LSPACE
READ (*, '(A)') TEXT
NCC = 0
LSPACE = .TRUE.
DO 1, I = 1,LEN(TEXT)
NC = ICHAR(TEXT(I:I))
IF (NC .GE. 65 .AND. NC .LE. 90 .OR.
> NC .GE. 97 .AND. NC .LE. 122) THEN
IF (LSPACE) THEN
IF (NC .GE. 97 .AND. NC .LE. 122) THEN
NC = NC - 32
END IF
ELSE
IF (NC .GE. 65 .AND. NC .LE. 90) THEN
NC = NC + 32
END IF
END IF
NCC = NCC + 1
CC(NCC:NCC) = CHAR(NC)
LSPACE = .FALSE.
ELSE
LSPACE = .TRUE.
END IF
1 CONTINUE
DO 2, I = NCC + 1,LEN(CC)
2 CC(I:I) = " "
WRITE (*, *) CC
END
Пример для версий Dart 1.1.1
splitMapJoin разбивает строку на части, соответствующие регулярному выражению, и части между ними, преобразует все фрагменты с использованием двух функций (в данном случае изменяет регистр соответствующих частей и заменяет несоответствующие на пустые строки) и конкатенирует результаты в новую строку.
import 'dart:io';
main() {
String text = stdin.readLineSync().toLowerCase();
String capitalize(Match m) => m[0].substring(0, 1).toUpperCase() + m[0].substring(1);
String skip(String s) => "";
print(text.splitMapJoin(new RegExp(r'[a-z]+'), onMatch: capitalize, onNonMatch: skip));
}
Пример для версий Wouter's FALSE 1.2.CF
Этот пример аналогичен примеру для Morphett’s FALSE, за исключением того, что в Wouter’s FALSE 1.2.CF признаком конца ввода является конец строки, поэтому условие продолжения цикла использует сравнение с 10. Кроме того, % в конце программы очищает стек от оставшегося там значения.
1_s: ^
[$10=~]
[ $$ 96> \123\> & [32-]?
$$ 64> \91\> & $l: [s;~[32+]? , 0s:]? l;~[1_s: %]?
^]
#
%
Пример для версий Snap! 4.0
Snap! предоставляет более богатый набор встроенных блоков, чем Scratch, например, в него входят блоки unicode of _ и unicode _ as letter. Для удобства эти блоки использованы для определения блоков isLetter, toLower и toUpper, аналогичным одноименным функциям в других языках.
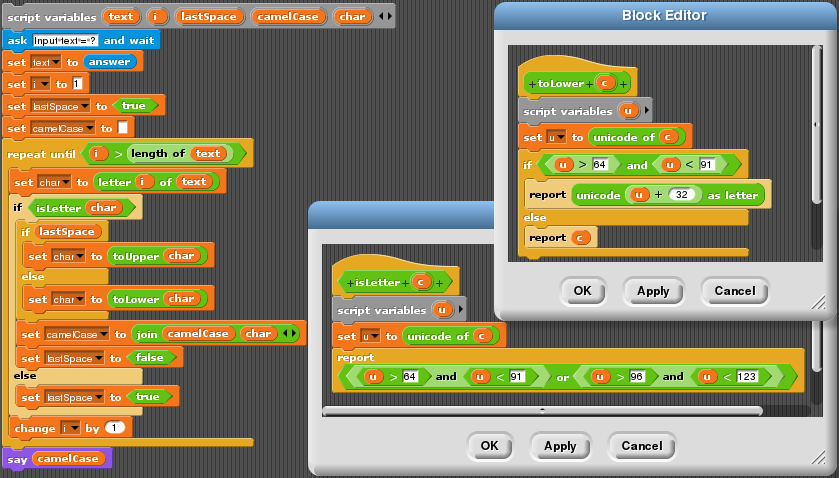
CamelCase на Snap!
Пример для версий Clarion C7
PROGRAM
MAP
END
InitStr STRING('Some string with any symbols')
Str CSTRING(100),AUTO
symbol STRING(1)
CODE
j# = 1 ! implicit variable
loop i# = 1 to len(InitStr) by 1
symbol = lower(InitStr[i#]) ! string can be considered as array
case symbol
of 'a' to 'z'
Str[j#] = choose(was_letter#,symbol,upper(symbol))
j# += 1 ! using of add equals operator for increment
was_letter# = TRUE
else
was_letter# = FALSE
end
end
message(Str,'CamelCase')